| Sample of the dataset cleaned | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| The sample was stratified by the variables donation_type and gender | ||||||||||
| donor class | donation type | birth year | birth cohort | first donation year | first donation cohort | number of donations | gender | year | age | unique number |
| O | SANGUE | 1997 | 1995 | 2015 | 2015 | 1 | F | 2015 | 18 | 27070713 |
| P | PLASMAF | 1962 | 1960 | 2012 | 2010 | 4 | M | 2017 | 55 | 26993175 |
| P | SANGUE | 2004 | 2000 | 2022 | 2020 | 1 | M | 2023 | 19 | 27221766 |
| P | AFPLTPLASM | 1976 | 1975 | 2012 | 2010 | 4 | F | 2017 | 41 | 27002244 |
| P | PLASMAF | 1969 | 1965 | 2001 | 2000 | 2 | F | 2019 | 50 | 26484318 |
| P | AFPLTPLASM | 1973 | 1970 | 2006 | 2005 | 5 | M | 2022 | 49 | 26849700 |
| P | PLTAFE | 1986 | 1985 | 2010 | 2010 | 1 | M | 2016 | 30 | 26956035 |
| P | PLTAFE | 1967 | 1965 | 1992 | 1990 | 2 | F | 2016 | 49 | 26486637 |
1 Introduzione
L’obiettivo di questa tesi è proporre e validare empiricamente un framework statistico per la previsione delle donazioni di sangue nel territorio Giuliano-Isontino, con orizzonte annuale.
Nella pratica quotidiana i centri trasfusionali devono rispondere alla domanda clinica garantendo un buffer di scorte: sovrastimare i lotti in scadenza comporta costi di smaltimento, mentre sottostimare la raccolta può generare situazioni critiche con rinvii di interventi chirurgici programmati.
Pertanto, è cruciale disporre di strumenti predittivi che stimino:
la probabilità che un donatore torni a donare l’anno successivo;
la distribuzione del numero di donazioni attese per singolo individuo;
i profili latenti di comportamento (frequente, saltuario e non-donatore) e la loro evoluzione nel tempo.
Lo studio si occuperà dello studio dei punti sopracitati, focalizzandosi soprattutto nell’ultimo.
La tesi si articola in due nuclei metodologici:
Generalized Linear Models (GLM) per stimare il numero cumulato di donazioni nell’orizzonte storico, con diverse famiglie di distribuzione (quasi-Poisson, Tweedie, Gamma, …).
Hidden Markov Models bayesiani con covariate, in cui il numero di donazioni annue è trattato come emissione di una variabile di stato latente.
A corredo dei modelli è stata sviluppata una dashboard interattiva con Quarto e Shiny che consente al personale medico di:
predire il flusso futuro di donazioni;
predire le donazioni future di nuovi donatori;
filtrare la popolazione (età, genere, anno di prima donazione, ecc.);
1.1 Struttura della tesi
La tesi è strutturata in 6 capitoli:
il primo, ovvero il seguente, introduce la tesi e descrive la parte preliminare di analisi e pulizia del dato. Parte fondamentale per i capitoli successivi;
la seconda parte, introduce i modelli lineari generalizzati, analizzandoli dal punto di vista teorico e pratico. Il capitolo analizzerà diverse distribuzioni applicate sempre allo stesso modello, mettendo in luce pregi e diffetti di ciascuna di esse;
il terzo capitolo rappresenta il cuore della tesi: in esso viene costruito il modello finale del progetto, una combinazione di diversi elementi. Si utilizza un modello markoviano a stati latenti con modelli lineari generalizzati sulle emissioni e un approccio bayesiano applicato alle probabilità iniziali e alla matrice di transizione;
il quarto, si dedicherà alla parte pratica del progetto, la messa in produzione del modello. Descriverà il processo di costruzione di una dashboard per permettere al personale medico l’utilizzo del modello in tempo reale;
l’ultimo capitolo raccoglierà le somme del progetto, mettendo in luce i punti di forza e i talloni d’achille del progetto. Inoltre, si analizzeranno idee future per ulteriori implementazioni e approffondimenti.
1.2 I Dati
La raccolta dati è fondamentale per poter elaborare un framework statistico a supporto dei strumenti predittivi e questi dati è possibile raccoglierli grazie a tutto il sistema che ruota attorno al processo della donazione di sangue. Per poter donare il sangue in Italia c’è appunto un sistema di stakeholder del settore pubblico (regioni, centri ospedalieri), privato (associazioni non profit) e cittadini che contribuiscono attivamente al buon esito di questo processo (Guglielmetti Mugion et al. (2021)). La creazione del Centro Nazionale Sangue (CNS) e del Registro nazionale del sangue nel 2007 ha trasformato l’assetto organizzativo della donazione del sangue in Italia. Il CNS è stato istituito con Decreto del Ministro della Salute del 26 aprile 2007 e ha iniziato il suo mandato il 1° agosto dello stesso anno. Il CNS svolge funzioni di coordinamento e controllo tecnico-scientifico del sistema trasfusionale nazionale nelle materie disciplinate dalla legge n. 219 del 21 ottobre 2005 “Nuova disciplina delle attività trasfusionali e della produzione nazionale degli emoderivati” e dai decreti di trasposizione delle direttive europee. All’interno di tale sistema sono presenti le Strutture Regionali di Coordinamento per le attività trasfusionali (SRC). Le SRC sono strutture tecnico-organizzative delle Regioni e Province Autonome che garantiscono il supporto alla programmazione nazionale in materia di attività trasfusionali e il coordinamento e controllo tecnico-scientifico della rete trasfusionale regionale, in sinergia con il Centro Nazionale Sangue. Queste strutture regionali, anche definite Centri Regionali Sangue, detengono la responsabilità della raccolta e gestione delle donazioni di sangue a livello regionale (Bordandini (2025)). Dopo le riforme degli anni novanta (D.Lgs. 502/92 e 517/93) c’è stato un importante riassetto del sistema sanitario nazionale con uno spostamento della gestione verso le Regioni. In Friuli Venezia Giulia con la Legge Regionale 22/2019 viene riordinato il Sistema Sanitario Regionale dove a seguito di un decreto attuativo il 1° gennaio 2022 viene istituita l’Azienda Sanitaria Universitaria Giuliano Isontina (ASUGI) dalla quale attingeremo la maggior parte dei dati per l’elaborazione della nostra tesi.
Il campione statistico che andremo ad analizzare è quello dei donatori di sangue che in Italia è rappresentato dalle persone che possono donare e più precisamente con un’età compresa tra i 18 e i 65 anni, con un peso corporeo superiore ai 50 kg e in buono stato di salute. Gli uomini e le donne non in età fertile possono donare sangue intero ogni 3 mesi, mentre le donne in età fertile possono farlo 2 volte l’anno.
A livello quantitativo ci troviamo di fronte ad un elevato numero di donatori, circa 1,7 milioni nel 2024 (Nomisma (2024)). Ciò è dovuto anche grazie alle attività di supporto offerta dalle associazioni attive nel campo delle donazioni, come AVIS (Associazioni Volontari Italiani Sangue), FRATRES (Consociazione Nazionale dei Gruppi Donatori di Sangue Fratres delle Misericordie d’Italia), FIDAS (Federazione Italiana Associazioni Donatori di Sangue), Croce Rossa Italiana. Queste organizzazioni svolgono un ruolo cruciale nel promuovere attivamente la pratica della donazione del sangue: sebbene la decisione di donare sia una scelta individuale, è infatti importante sottolineare il ruolo essenziale che esse svolgono nell’informare e nel fungere da ponte tra le istituzioni (scuole incluse) e i cittadini (Bordandini (2025)). Attraverso diversi studi, analizzati dalla Bordandini, è stato possibile definire come fondamentale il lavoro svolto dalle diverse associazioni appena citate, per l’incremento di capitale sociale sia costruendo relazioni con le istituzioni locali, sia creando partecipazione e attivazione attraverso diverse iniziative che mirano allo sviluppo di senso di comunità e appartenenza (Saturni, Fiorentini, e Ricciuti (2017)). È stato visto che agevolazioni quali la Legge 584 del 1967, che ha stabilito il riconoscimento del diritto a una giornata di riposo dal lavoro e alla piena retribuzione al donatore di sangue, piuttosto che lo stesso riconoscimento sociale motivato dal confronto con amici e familiari, ma anche l’aver ricevuto trasfusioni o conoscere qualcuno che ha beneficiato di una trasfusione hanno avuto un impatto significativo, aumentando la frequenza delle donazioni e la propensione a persuadere altri a donare(Bordandini (2025)).
A fronte di quanto appena esposto, ai fini dei strumenti predittivi oggetto di questa tesi, è importante tenere conto delle variabili che andremo di seguito ad analizzare.
Fonte ed Elaborazione
| campo | descrizione |
|---|---|
donor_class |
classificazione del donatore |
donation_type |
categoria (SANGUE, PLASMA, PIASTRINE, …) |
birth_year |
anno di nascita |
birth_cohort |
coorte di nascita, generazione (1970, 1975, 1980, …) |
first_donation_year |
anno della prima donazione registrata |
first_donation_cohort |
coorte della prima donazione registrata |
number of donations |
numero di donazioni effettuate nel determinato anno |
gender |
M/F |
year |
anno di riferimento delle donazioni |
age |
età del donatore |
unique_number |
identificativo anonimo del donatore |
I dati provengono dall’estrazione e anonimizzazione di dati provenienti dal data warehouse dell’Azienda Sanitaria Universitaria Giuliano Isontina (ASUGI). I dati vengono forniti in file Excel (formato xlsx) e subiscono un iniziale processo di unificazione ed esportazione in formato tabellare (csv). Il dataset primario contiene le donazioni fatte da un individuo in un determinato anno, corredate di ulteriori informaizoni, riportate nella Tabella 1.1.
Anche se i dati provengono da un data warehouse che segue protocolli rigorosi nella gestione delle informazioni, è comunque necessaria una fase di ETL (Extract, Transform, Load). Questa consiste nell’estrazione e trasformazione dei dati per adattarli e arricchirli in base alle esigenze specifiche del progetto. Il lavoro viene eseguito utilizzando il linguaggio di programmazione statistica R (R Core Team (2023)) e la libreria tidyverse, che offre funzioni per la manipolazione efficiente dei dati, garantendo al contempo leggibilità del codice e velocità di esecuzione. (Wickham et al. (2019))
La tabella originale è composta da 268.530 righe, una per ogni donatore e per ogni anno nella quale abbia donato, contenendo il numero di donazioni effettuate, il tipo di donazione e le caratteristiche del donatore. Sono presenti record duplicati (171.378).
I passi principali compiuti sono i seguenti:
rimozione record duplicati;
sostituzione di
NAcon 0 nei conteggi annuali;derivazione di età =
year-birth_yeare classi d’età quinquennali;standardizzazione (
z-score) dibirth_yeareageper facilitare la convergenza dell’ottimizzatore nei modelli bayesiani;aggiunta della variabile dummy Covid;
creazione di tre matrici di covariate:
\(x^\pi\) (fisse per donatore): anno di nascita e genere;
\(x^A_{t}\) (tempo-varianti): età categorica e dummy Covid;
\(x^{em}_{t}\) (tempo-varianti): età categorica, dummy Covid e genere.
La derivazione dell’età sarà utile per avere una variabile dinamica, che varia nel tempo. Infatti si presuppone che la propensione al donare vari con l’età del donatore, ed avendo osservazioni pluriennali, si ritiene opportuno tenere in considerazione ciò. Però, anche il fattore generazionale può influire, ovvero una persona di 50 anni del 1970 può avere una propensione nel donare diversa di un cinquantenne nato 10 anni prima. Questo potrebbe essere dovuto da fattori generazionali e anch’esso andrà incluso nelle analisi. Infine, in molte analisi condotte, è stata utilizzata la variabile età come categoriale, anziché numerica.
Nei primi 10 giorni di marzo 2020, all’inzio della pandemia SARS-CoV-2, le donazioni di sangue in Italia sono state quasi nulle, per poi passare ad un forte aumento. Il Centro Nazionale Sangue (CNS), l’autorità nazionale competente, pubblicò linee guida chiare per permettere la continuazione dei prelievi di sangue ed evitare un’interruizione della catena di approvigionamento della raccolta di materiale trasfusionale. (Pati et al. 2021) Lo studio analizzerà con attenzione l’impatto della pandemia sul flusso delle donazioni e sui donatori.
Infine, le osservazioni vengono aumentate, ossia vengono aggiunte le donazioni pari a 0 negli anni in cui non abbiamo il dato di uno specifico donatore. Si ipotizza che quando il dato non venga raccolto non ci siano donazioni da parte dell’individuo. Questa è un’ipotesi forte, infatti ci potrebbero essere diverse ragioni per la mancanza del dato e non solo la mancata donazione. Ad esempio, l’individuo si sarebbe potuto trasferire, o avrebbe potuto decidere di donare in un centro trasfusionale differente da quello da noi analizzato, ossia il centro trasfusionale dell’ASUGI.
Analisi Preliminare
L’Italia, come molti altri paesi del mondo, è affetta dal fenomeno generazionale del baby boom, ovvero da un notevole incremento delle nascite negli anni 50-60, dovuto a vari fattori, tra cui la forte crescita economica. Questo fenomeno è oggetto di studio in diversi ambiti, uno tra i quali è l’ambito assicurativo, dove ci si preoccupa se le generazioni più giovani saranno in grado di sopportare il sistema pensionistico quando i baby boomers andranno in pensione. Lo stesso discorso vale per le donazioni di sangue, in quanto i donatori saranno meno e coloro che necesiteranno di sacche di sangue sarà sempre maggiore. Questo fenomeno generazionale si può osservare dalla Figura 1.1 dove si osserva uno spostamento nella “gobba” verso l’alto dal 2009 al 2023.
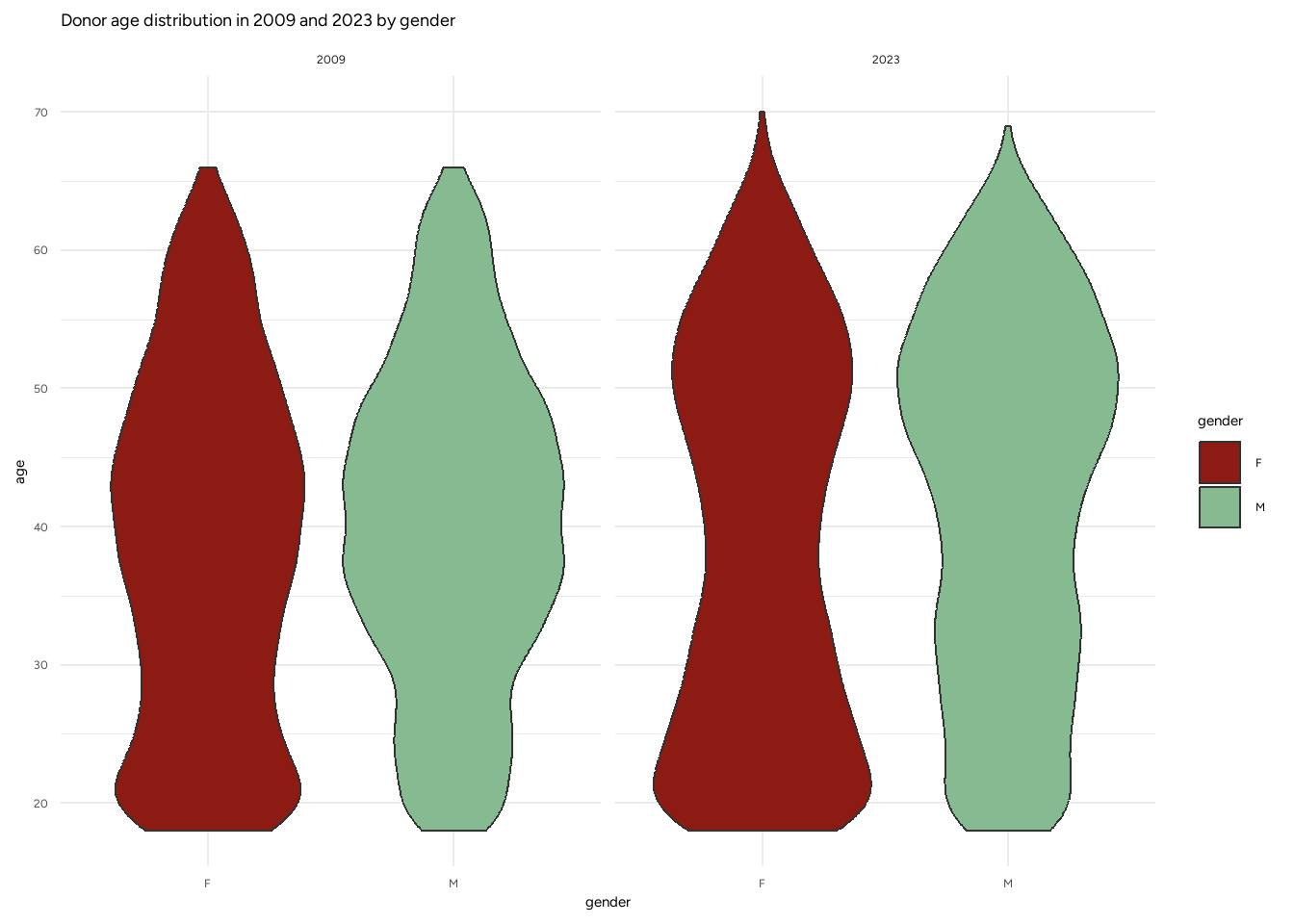
Le donazioni provengo maggiormente dagli uomini, tuttavia si osserva (vedi Tabella 1.3) come questo gap si sti riducendo nelle nuove generazioni, grazie anche alla efficace comunicazione dei centri di trasfusione.
F
|
M
|
|||
|---|---|---|---|---|
| 2009 | 2023 | 2009 | 2023 | |
| [18,25] | 896 | 976 | 1490 | 1282 |
| (25,35] | 672 | 679 | 2595 | 1793 |
| (35,45] | 846 | 517 | 3943 | 1673 |
| (45,55] | 739 | 832 | 2938 | 2759 |
| (55,65] | 483 | 510 | 1248 | 1659 |
| (65,70] | 2 | 26 | 32 | 47 |
1.3 Integrazione dei Dati
Le analisi appena eseguite sono state condotte sui donatori e le loro donazioni, mostrandoci caratteristiche e pattern fondamentali sulle donazioni. Per un’analisi più approfondita è necessario tenere in considerazione anche quella parte di popolazione che non dona, e che, di conseguenza, non risulta essere presente nei dati a noi disponibili.
L’obiettivo è di integrare il database che possediamo con ulteriori informazioni che potrebbero arrichire le analisi e aggiungere informazioni ai modelli.
I dati in nostro possesso sono la raccolta delle donazioni presso le strutture sanitarie dell’ASUGI, ovvero dell’Azienda Sanitaria Universitaria Giuliano Isontina, ovvero che i dati in nostro possesso provengono dai centri trasfusionali del territorio di Trieste e Gorizia. Tuttavia, ciò non indica che le donazioni provengano da cittadini residenti nel territorio Giuliano-Isontino. Infatti, le donazioni sono aperte a tutti, anche a cittadini stranieri, come potrebbe essere uno studente durante il suo progetto Erasmus a Trieste. Andranno fatte, dunque, delle assunzioni per semplificare la realtà. Si ipotizzerà che le donazioni provengono solo da residenti del territorio. Potremo così integrare i dati con le informazioni sui residenti.
Le informazioni provengono dal database pubblico dell’Istituto Nazionale di Statistica, ISTAT. I dati in formato tabulare contengono informazioni di vario tipo, tra cui il genere, l’anno, la popolazione e lo stato civile. I dati verranno processati e adattati ai dati sulle donazioni di sangue per poi unirli con essi.
Stima dei Residenti Passati
Nel database di ISTAT disponibile online si possono trovare solamente le serie complete per il 2019–2023 riguardo la popolazione residente per genere, età e provincia. Il nostro dataset, invece, copre il periodo a partire dal 2009 fino al 2023, un tempo decisamente più largo. Per ricostruire a ritroso la popolazione residente nel capoluogo giuliano adottiamo un approccio in due passi. Primo, richiamamo l’identità di bilancio demografico, che regola l’evoluzione della popolazione residente (cfr. ISTAT (2023a)):
\[ P_t = P_{t-1} + N_t - M_t + I_t - E_t \tag{1.1}\]
dove \(P_t\) è la popolazione a fine anno \(t\), \(N_t\) i nati vivi, \(M_t\) i decessi, \(I_t\) gli iscritti per migrazione ed \(E_t\) i cancellati per migrazione.
Per ricostruire a ritroso la popolazione residente nel capoluogo giuliano (2009–2018) adottiamo il metodo di retroproiezione per coorti (“reverse life-table”), che utilizza i sopravviventi \(l_x\) dalle tavole di mortalità per risalire alla consistenza delle coorti alle età precedenti (Caselli, Vallin, e Wunsch (2006); per definizioni e stima di \(l_x\) nelle tavole ISTAT si veda ISTAT (2023b)). I valori \(l_x\) sono prese dalle tavole di mortalità “SIM/SIF 02”, tavole di riferimento per la popolazione italiana. La formulazione operativa impiegata è:
\[ n_{x}^{y_i} = n_{\,x-(y_i-y_j)}^{\,y_j}\, \frac{\,l_x}{l_{\,x-(y_i-y_j)}} \,, \tag{1.2}\]
dove \(n_x^{y_i}\) è la popolazione alla’età \(x\) al tempo \(y_i\), \(n_{x-(y_i-y_j)}^{y_j}\) è l’effettivo della medesima coorte alla età \(x-(y_i-y_j)\) osservato (o stimato) al tempo \(y_j\), e il rapporto \(\frac{l_x}{l_{x-(y_i-y_j)}}\) rappresenta la probabilità di sopravvivenza tra le due età secondo la tavola di mortalità di riferimento. In mancanza di flussi migratori comunali completi, si assume una migrazione netta nulla.
Nota sulle tavole SIM/SIF 02
Con “SIM/SIF 02” si fa riferimento a una delle serie ufficiali di tavole di mortalità pubblicate da ISTAT, per età singola e per sesso, che riportano le principali funzioni di tavola (in particolare i sopravviventi \(l_x\), le probabilità \(q_x\), i decessi \(d_x\) e gli esposti \(L_x\)) e costituiscono la base standard per calcoli di sopravvivenza e retroproiezione a livello nazionale.
Unione dei Dati
La join tra il registro dei donatori e il dataframe con i residenti consente di costruire un indicatore di “penetrazione” (quota di donatori sulla popolazione residente), disaggregato per anno, classe d’età e genere. Indichiamo con \(\#\text{donatori}(a,y,g)\) il numero di individui presenti nel dataset in quella cella \((a,y,g)\) e con \(\text{residenti}(a,y,g)\) il denominatore demografico coerente (stessa cella di età, anno e genere). Definiamo quindi:
\[ \text{penetration}_{a,y,g} = \frac{\#\text{donatori}(a,y,g)}{\text{residenti}(a,y,g)}, \qquad g\in\{F,M\},\; a=\text{classe d’età},\; y. \]
Nel seguito, per il grafico (Figura 1.2) lavoriamo su età singola, mentre per la tabella (Tabella 1.4) aggreghiamo a classi decennali. Si noti che la coerenza del denominatore è garantita dall’integrazione con i residenti ISTAT per la medesima triade \((g,y,a)\).
Il rapporto tra donatori e popolazione residente permette di analizzare i dati in modo relativo, eliminando differenze nella popolazione, come il feonomeno del baby boom osservato in Sezione 1.2.2. Il grafico mostra l’elevato picco che c’è attorno ai 20 anni, che successivamente va decrescendo, soprattutto nelle femmine. Si evidenzia un trend crescente nella fascia 18-25 delle femmine passando in 12 anni dal 5,36% al 6,5% (+21%), questo trend è ancor più forte per la fascia 25-35 dove la percentuale di donatrici è più che raddoppiata passando dal 2,63% al 5,64%. Per gli uomini si osserva, invece, un leggero calo nel rapporto tra donatori e popolazione negli ultimi che, però, rimangono in termini assoluti e relativi superiori alle femmine per ogni fascia d’età.
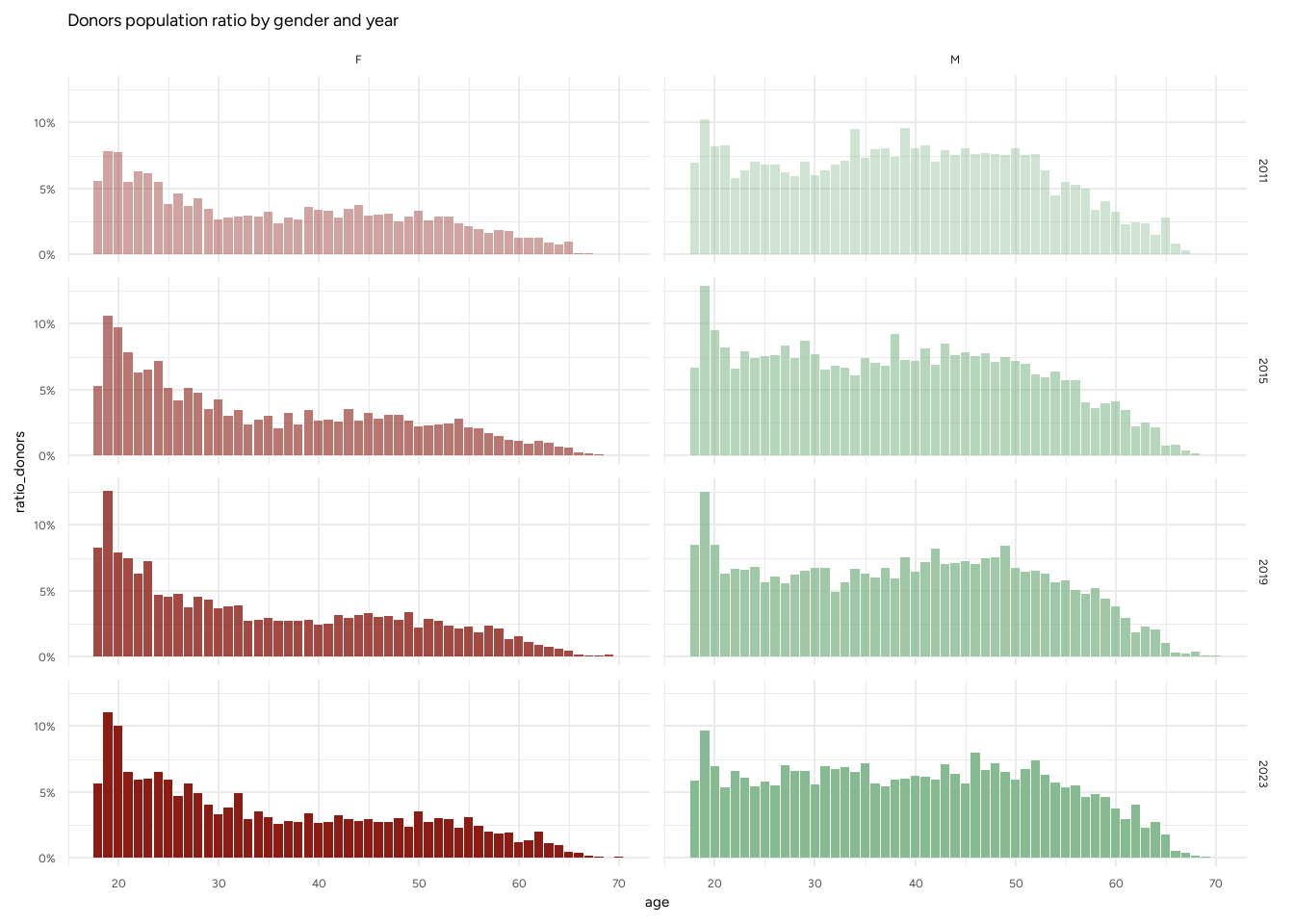
F
|
M
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2011 | 2014 | 2017 | 2020 | 2023 | 2011 | 2014 | 2017 | 2020 | 2023 | |
| [18,25] | 5,4% | 5,3% | 5,9% | 5,4% | 6,5% | 7,2% | 6,7% | 6,6% | 6,3% | 6,2% |
| (25,35] | 2,6% | 2,6% | 3,1% | 3,1% | 3,2% | 6,2% | 5,8% | 5,6% | 5,5% | 5,8% |
| (35,45] | 2,1% | 1,9% | 1,9% | 1,9% | 2,2% | 6,6% | 6,0% | 5,8% | 5,4% | 4,9% |
| (45,55] | 1,9% | 1,6% | 1,9% | 1,9% | 2,1% | 5,8% | 5,1% | 5,2% | 5,0% | 5,1% |
| (55,65] | 1,1% | 0,9% | 1,1% | 1,2% | 1,2% | 2,6% | 2,5% | 2,9% | 3,1% | 3,1% |
| (65,70] | 0,1% | 0,1% | 0,1% | 0,1% | 0,1% | 0,6% | 0,4% | 0,3% | 0,3% | 0,3% |
Nel 2002, Cartocci riportava un tasso di donatori pari a 384 per 10.000 residenti in tutta Italia; successivamente, i dati sintetizzati da Paola Bordandini (vedi Bordandini (2025)) indicano un incremento a 438 nel 2009 e a 454 nel 2022. Sulle nostre elaborazioni per Trieste - calcolate come rapporto tra donatori unici annui e residenti ISTAT nello stesso anno (per età e genere, poi aggregati) - il tasso complessivo risulta pari a 230 per 10.000 nel 2009, raggiunge un minimo di 216 nel 2021 e risale a 223 nel 2023, segnalando un lieve impatto congiunturale della pandemia e successivamente recuperato. Questo valore più basso della media nazionale può esser dovuto a diversi fattori, il principale è probabilmente la forte asimmettria nelle fasce d’età, favorendo le fasce più anziane che sono fuori dal ciclo donativo.
Se il tasso è stabile, purtroppo non si può dire lo stesso per il numero assoulto di donazioni, in quanto il numero di potenziali donatori continua a diminuire e il numero di coloro che ne hanno bisogno è in continuo aumento. Scopo di questa tesi è, percò, costruire uno strumento usufruibile dal personale medico per prevenire l’abbandono del ciclo donativo da parte dei donatori ed incrementare, ove possibile, il numero di donazioni annue da parte del donatore.
Caselli, Graziella, Jacques Vallin, e Guillaume Wunsch. 2006. Demografia. Analisi e sintesi. Bologna: Il Mulino.
Guglielmetti Mugion, Roberta, Maria Giovina Pasca, Laura Di Pietro, e Maria Francesca Renzi. 2021. «Promoting the propensity for blood donation through the understanding of its determinants». BMC Health Services Research 21 (1): 127. https://doi.org/10.1186/s12913-021-06134-8.
ISTAT. 2023a. «Bilancio demografico e popolazione residente: definizioni e note metodologiche». Roma: Istituto Nazionale di Statistica.
———. 2023b. «Tavole di mortalità della popolazione residente: metodi e note tecniche». Roma: Istituto Nazionale di Statistica.
Nomisma. 2024. «Osservatorio Nazionale Donazione Sangue e Plasma». https://www.nomisma.it/press-area/osservatorio-nazionale-donazione-sangue-e-plasma/.
Pati, Ilaria, Claudio Velati, Carlo Mengoli, Massimo Franchini, Francesca Masiello, Giuseppe Marano, Eva Veropalumbo, et al. 2021. «A forecasting model to estimate the drop in blood supplies during the SARS‐CoV‐2 pandemic in Italy». Transfusion Medicine 31 (marzo): 200–205. https://doi.org/10.1111/tme.12764.
R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Saturni, Vincenzo, Giorgio Fiorentini, e Elisa Ricciuti. 2017. La Vis di Avis: La Valutazione di Impatto Economico e Sociale dell’Associazione Volontari Italiani del Sangue. FrancoAngeli.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. «Welcome to the tidyverse». Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.